

Data Science Workflows: Praktische Tipps
Ein erfolgreicher Data Science Workflow erfordert sorgfältige Planung und präzise Ausführung.
Wir bei Newroom Media haben praktische Tipps zusammengestellt, um dich durch die wichtigsten Schritte zu führen.
Von der Problemdefinition bis zur Integration der Modelle decken wir alle entscheidenden Phasen ab.
Lass uns gemeinsam die besten Praktiken und Tools erkunden, die dir helfen, den Workflow zu meistern.
Wie startest du den Data Science Workflow?
Ein erfolgreicher Start eines Data Science Workflows beginnt mit einer klaren Problemdefinition und Zielsetzung. Hier solltest du präzise festlegen, welches Problem gelöst werden soll und welche Ziele du dabei verfolgst. Eine gut formulierte Problemstellung erleichtert später die Auswahl der passenden Modelle und Techniken.
Problemdefinition und Zielsetzung
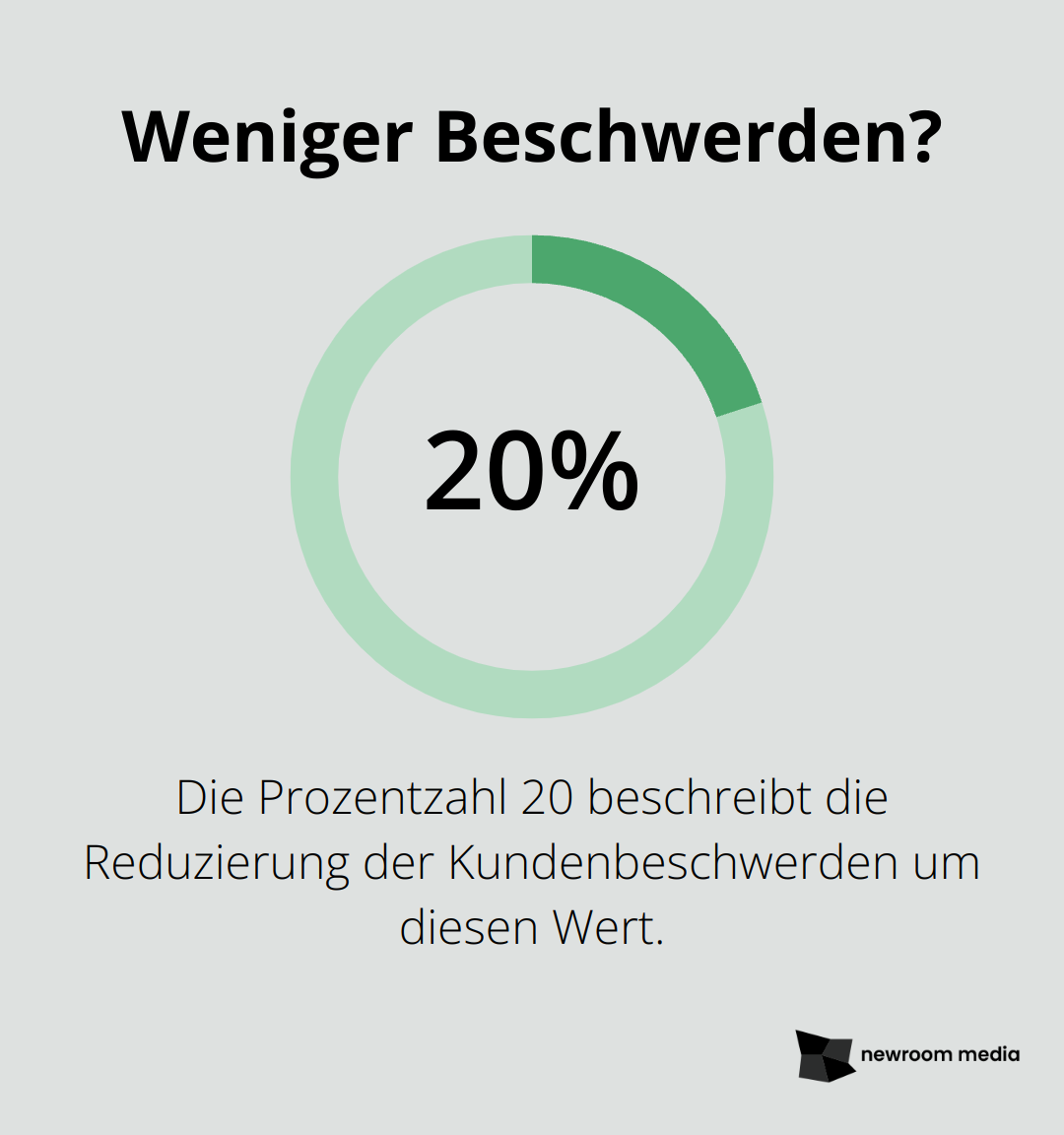
Denke daran, die Problemstellung so konkret wie möglich zu formulieren. Anstatt „Verbesserung der Kundenzufriedenheit“ solltest du beispielsweise „Reduzierung der Kundenbeschwerden um 20% in den nächsten sechs Monaten“ anstreben. Diese Klarheit hilft dir, später Erfolge besser zu messen.
Datenbeschaffung und Datenaufbereitung
Ein wesentlicher Teil der Arbeit von Datenwissenschaftlern, etwa 70-80% der Arbeitszeit, fließt in die Datenbeschaffung und -aufbereitung. Hierbei ist es wichtig, die Datenquellen gründlich zu prüfen und sicherzustellen, dass die Daten sauber und relevant sind. Automatisierungswerkzeuge können die Datenaufbereitung erheblich beschleunigen und die Fehlerquote reduzieren. Tools wie Apache NiFi oder Talend sind hier nützlich.
Inline-Visualisierungen sind ein praktisches Mittel, um bereits bei der Datenaufbereitung Fehler zu erkennen und zu korrigieren. Dienste wie Databricks oder Jupyter Notebooks ermöglichen es dir, Daten schnell zu analysieren und zu visualisieren.
Auswahl der geeigneten Tools und Technologien
Die Wahl der Tools hängt stark von deinen spezifischen Anforderungen ab. Python ist ein unverzichtbares Werkzeug für viele Data Scientists, da es zahlreiche Bibliotheken wie pandas für die Datenmanipulation und scikit-learn für das maschinelle Lernen bietet.
Wenn du auf der Suche nach Workflow-Engines bist, könnten Argo und Pachyderm interessante Optionen sein. Beide bieten systematische Analysemöglichkeiten und lassen sich gut in bestehende Infrastrukturen integrieren. Denk daran, dass die Anforderungen an deine Tools und Technologien von deinem spezifischen Anwendungsfall abhängen. Für eine detaillierte Bewertung, schau doch mal hier.
Durch die sorgfältige Planung und Vorbereitung deines Data Science Workflows legst du den Grundstein für den Erfolg. Nimm dir Zeit für diese ersten Schritte, denn sie bestimmen maßgeblich den weiteren Verlauf und den finalen Erfolg deines Projekts.
Wie führst du die Analyse durch?
Exploration der Daten und erste Analysen
Ein gründliches Verständnis deiner Daten ist der Schlüssel zur erfolgreichen Analyse. Beginne damit, deine Daten zu erkunden und grundlegende Statistiken zu berechnen. Werkzeuge wie pandas in Python helfen dir, Deskriptivstatistiken schnell zu berechnen und erste Muster zu erkennen.

Datenvisualisierung spielt hierbei eine wichtige Rolle. Nutze Matplotlib oder Seaborn, um grafische Darstellungen zu erstellen. Dadurch kannst du Ausreißer, Trends und Korrelationen leichter erkennen. Inline-Visualisierungen in Jupyter Notebooks können dir helfen, sofortige Einblicke direkt während der Analyse zu gewinnen.
Modellierung und Hypothesenprüfung
Jetzt kommt der spannende Teil: die Modellierung. Wähle geeignete Modelle basierend auf der Art des Problems und den verfügbaren Daten. Für Klassifizierungsprobleme könnten Algorithmen wie Random Forests oder Support Vector Machines nützlich sein. Für Regressionsprobleme bieten sich lineare Modelle oder Gradient Boosting an.
Nutze Bibliotheken wie scikit-learn für die Implementierung deiner Modelle. Eine strikte Trennung von Trainings- und Testdaten ist entscheidend, um Overfitting zu vermeiden und die Generalisierungsfähigkeit deines Modells zu prüfen.
Neben der Modellierung ist die Hypothesenprüfung ein wichtiger Schritt. Formuliere klare Hypothesen und teste sie statistisch. Tools wie SciPy oder Statsmodels in Python bieten dir umfangreiche Möglichkeiten zur Hypothesenprüfung.
Bewertung der Modellergebnisse und Feinabstimmung
Die Bewertung deiner Modelle erfolgt anhand von Metriken wie Genauigkeit, Präzision, Recall und F1-Score. Diese Metriken geben dir Aufschluss darüber, wie gut dein Modell auf den Testdaten performt. Nutze bibliotheksinterne Funktionen in scikit-learn, um diese Metriken zu berechnen.
Vergiss nicht, deine Modelle durch Hyperparameter-Tuning zu optimieren. Grid Search oder Random Search können dir helfen, die besten Parameterkombinationen zu finden. Dies kann die Performance deines Modells erheblich verbessern.
Pensier auch daran, deine Modellergebnisse sauber zu dokumentieren und zu visualisieren. Tools wie Jupyter Notebooks bieten dir eine gute Plattform, um deine Arbeit nachvollziehbar darzustellen.
Durch gezielte Exploration, sorgfältige Modellierung und umfassende Bewertung stellst du sicher, dass deine Analysen robuste und verlässliche Ergebnisse liefern.
Wie setzt du Modelle in die Produktion um?
Wenn deine Modelle fertig sind, geht es darum, sie in produktive Umgebungen zu bringen. Dabei gibt es einige bewährte Methoden, die dir helfen, den Übergang nahtlos zu gestalten.
Deployment der Modelle
Zunächst einmal solltest du sicherstellen, dass deine Modelle robust und skalierbar sind. Containerisierung ist hier oft der Schlüssel. Tools wie Docker ermöglichen es dir, Modelle in isolierten Umgebungen zu deployen, was die Portabilität zwischen verschiedenen Systemen erleichtert. Kubernetes kann dir dabei helfen, die Skalierbarkeit deiner Modelle zu gewährleisten, indem es die Ressourcenverteilung und -verwaltung automatisiert.

Für eine nahtlose Integration bietet sich die Verwendung von APIs an. Mit Tools wie Flask oder FastAPI kannst du deine Modelle als Dienste bereitstellen, die von anderen Anwendungen einfach angesprochen werden können.
Monitoring und Wartung
Sobald deine Modelle live sind, ist kontinuierliches Monitoring unerlässlich. Überwache die Performance deiner Modelle in Echtzeit mit Tools wie Prometheus und Grafana. Diese Tools geben dir tiefe Einblicke in wichtige Metriken wie Antwortzeiten, Fehlerquoten und Ressourcennutzung.
Regelmäßige Wartung ist ebenfalls wichtig, um sicherzustellen, dass deine Modelle nicht veralten. Plane feste Intervalle für die Neutrainierung der Modelle, um sie auf dem neuesten Stand zu halten. Automatisierungswerkzeuge wie MLflow können dabei helfen, den gesamten Lebenszyklus deiner Modelle zu verwalten, von der Versionierung bis hin zur Neutrainierung.
Berichterstattung und Kommunikation der Ergebnisse
Ein oft übersehener, aber entscheidender Teil ist die Berichterstattung. Stelle sicher, dass die Ergebnisse deiner Modelle klar und verständlich kommuniziert werden. Dashboards und Berichte, die mit Tools wie Tableau oder Power BI erstellt wurden, können den Stakeholdern helfen, die Impact der Modelle zu verstehen.
Neben der Visualisierung ist schriftliche Dokumentation wichtig. Halte fest, welche Schritte du unternommen hast, welche Methoden und Tools du verwendet hast und welche Ergebnisse erzielt wurden. Diese Dokumentation ist nicht nur für Transparenz wichtig, sondern auch für die kontinuierliche Verbesserung deines Workflows.
Durch gezielte Planung und den Einsatz der richtigen Tools kannst du sicherstellen, dass der Übergang von der Entwicklung zur produktiven Nutzung reibungslos abläuft und deine Modelle den gewünschten Mehrwert liefern.
Schlussfolgerung
Abschließend lässt sich sagen, dass ein erfolgreicher Data Science Workflow von einer gründlichen Planung und präzisen Ausführung abhängt. Die Schritte von der Problemdefinition und Datenaufbereitung über die Modellierung und Analyse bis hin zur Integration und Überwachung der Modelle sind entscheidend für den Erfolg.

Durch die klare Definition des Problems und die gründliche Beschaffung und Aufbereitung der Daten legst du den Grundstein für präzise und aussagekräftige Analysen. Inline-Visualisierungen und Automatisierungswerkzeuge können dabei helfen, die Datenqualität sicherzustellen und Einblicke frühzeitig zu gewinnen.
Die sorgfältige Auswahl der richtigen Tools und Modelle, unterstützt durch bewährte Bibliotheken und Techniken, trägt zur Genauigkeit und Zuverlässigkeit deiner Ergebnisse bei. Eine kontinuierliche Überwachung und regelmäßige Wartung der Modelle stellen sicher, dass sie stets aktuell und leistungsfähig bleiben.
Die dokumentierte Berichterstattung über deine Ergebnisse ist ebenso wichtig wie die eigentliche Analyse und hilft dir, die Ergebnisse klar und nachvollziehbar zu kommunizieren.
Zukünftig bleiben Data Science Workflows dynamisch und müssen sich an neue Technologien und Methoden anpassen. Bei Newroom Media unterstützen wir dich dabei, stets am Puls der Zeit zu bleiben und die besten Praktiken und Tools zu nutzen, um deine Projekte zum Erfolg zu führen. Erfahre mehr unter Newroom Media.
Setze das Gelernte aus diesem Beitrag praktisch um, indem du deine Workflows kontinuierlich überprüfst und anpasst. Halte dich an bewährte Schritte und nutze die empfohlenen Tools, um deine Data Science Projekte voranzutreiben.